
5 Library Python untuk Tingkatkan Produktivitas Data Scientist
Library Python ini dapat digunakan untuk mengotomatisasi berbagai tahap, mulai dari persiapan data hingga deployment model. Cari tahu di sini!
Table of Contents
Data science merupakan bidang yang penuh inspirasi namun juga penuh tantangan. Melakukan pra-pemrosesan data, pembersihan data, menggali temuan baru dari visualisasi data, serta melakukan tuning pada model dapat menjadi pekerjaan yang sangat menguras waktu.
Pada blog ini, kita akan membahas 5 library Python yang dapat membantu Anda mengotomatisasi berbagai langkah dalam analisis data. Hanya dengan beberapa baris kode, Anda sudah dapat menghasilkan laporan yang lengkap, menyesuaikan hiperparameter dengan mudah, bahkan mengimplementasikan model machine learning dengan cepat. Penggunaan library ini akan membantu Anda menghemat waktu sekaligus meningkatkan produktivitas.
SweetViz
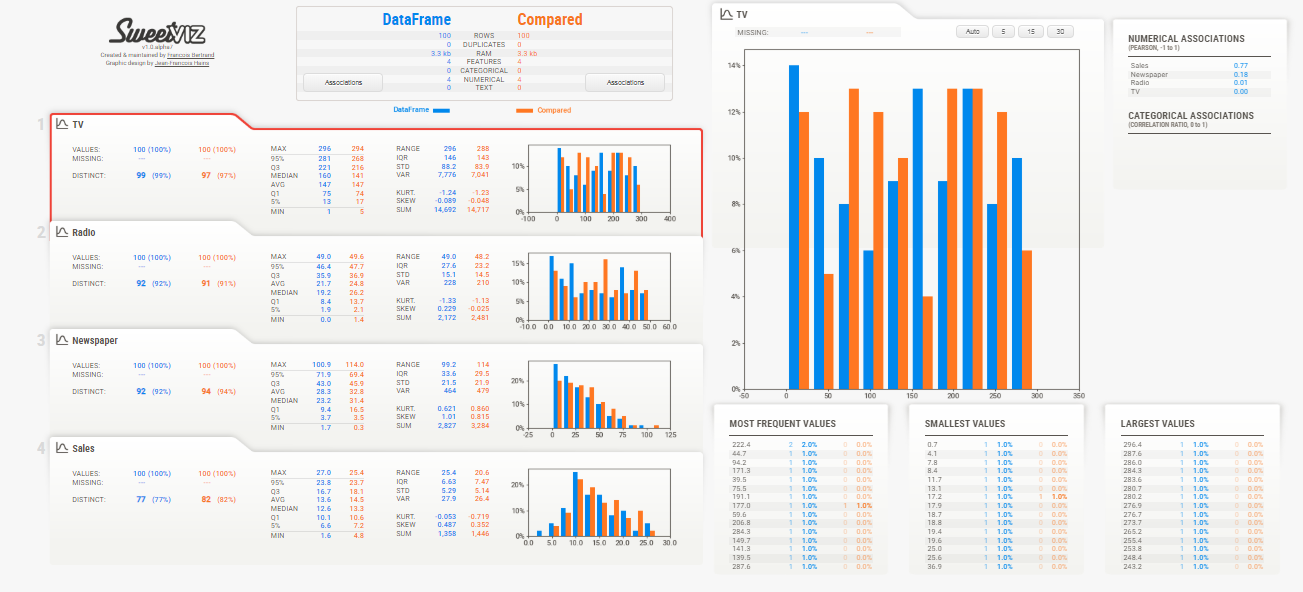
SweetViz merupakan library open-source berbasis Pandas yang dirancang khusus untuk melakukan Exploratory Data Analysis (EDA). Library ini memungkinkan Anda untuk membuat visualisasi dan membandingkan dataset untuk menunjang proses EDA. Dengan hanya dua baris kode, library ini mampu menghasilkan laporan komprehensif, lengkap dengan grafik yang relevan.
Laporan ini dapat dibuat dalam format HTML atau Jupyter Notebook, sehingga sangat mudah untuk dilihat dan dibagikan. Selain itu, dalam laporan ini juga dapat memuat berbagai jenis visualisasi HeatMaps untuk menganalisis korelasi variabel, histogram, dan visualisasi lainnya.
Selain itu, Anda memiliki fleksibilitas untuk menyesuaikan laporan sesuai kebutuhan, seperti menentukan variabel target, mengubah jenis grafik, atau bahkan merubah tata letaknya. Lebih lanjut, Anda dapat membandingkan dua dataset yang berbeda untuk menghasilkan insight baru.
Pandas Profiling
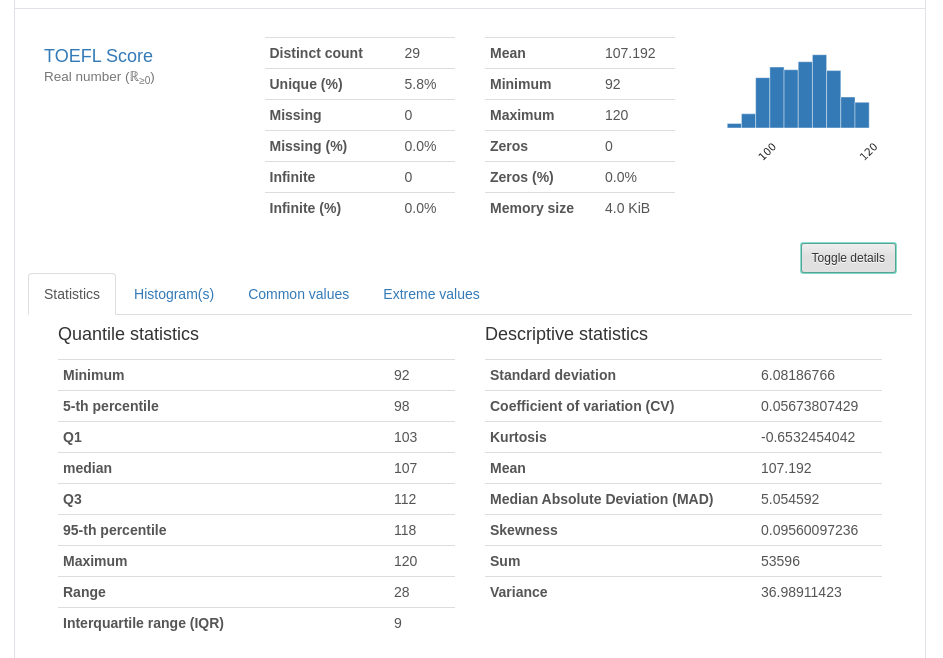
Library Pandas menyediakan beragam jenis fungsi yang berguna untuk menganalisis data. Meskipun demikian, menggunakan fungsi-fungsi tersebut satu per satu bisa memakan waktu yang cukup lama. Untuk mengatasi hal ini, Anda dapat menggunakan Pandas Profiling, yang mirip dengan SweetViz. Pandas Profiling mempermudah proses EDA dan menghasilkan laporan yang komprehensif hanya dengan beberapa baris kode.
Namun, yang membedakan keduanya adalah cara mereka memberikan wawasan tentang data. Pandas Profiling cenderung memberikan gambaran statistik yang lebih komprehensif dan mencakup banyak metrik statistik. Sementara itu, SweetViz unggul dalam melakukan perbandingan data secara visual karena menyediakan lebih banyak opsi kustomisasi untuk visualisasi.
Selain itu, perbedaan lainnya adalah Pandas Profiling memungkinkan Anda untuk mengekspor hasil analisis ke dalam format HTML dan json. Sementara SweetViz hanya mendukung ekspor ke format HTML dan Jupyter Notebook. Oleh karena itu, pemilihan antara kedua library bergantung pada jenis insight yang Anda butuhkan dan preferensi Anda dalam hal kustomisasi dan berbagi hasil analisis.
LazyPredict
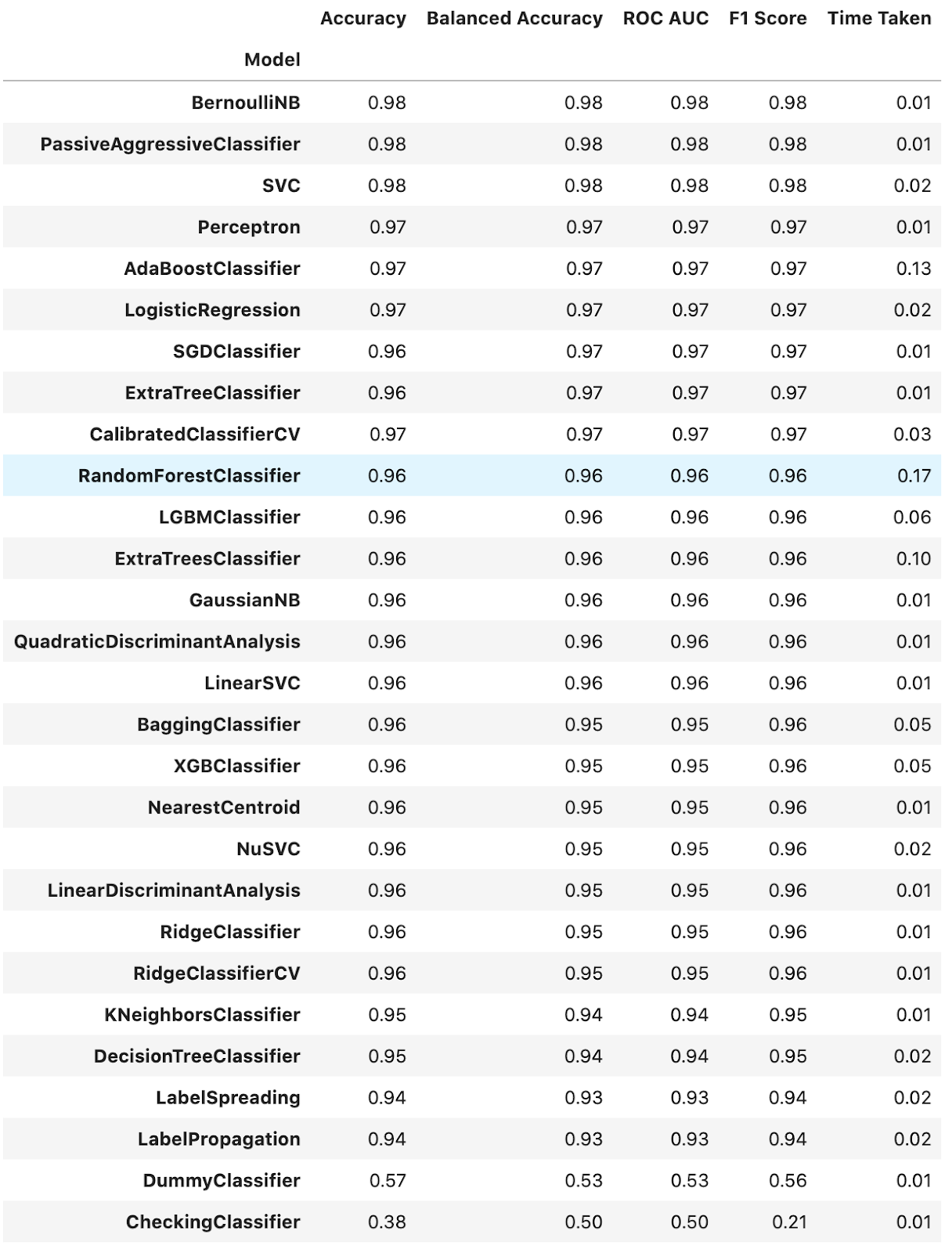
Selain melakukan analisis data, seorang data scientist seringkali diharuskan untuk membuat model machine learning. Proses mengimpor dan melatih model secara manual dapat menjadi pekerjaan yang melelahkan. Disinilah kegunaan library LazyPredict muncul.
LazyPredict merupakan sebuah library open-source yang berfungsi untuk membandingkan berbagai jenis model tanpa melakukan tuning hyperparameter secara manual. Dengan hanya beberapa baris kode, Anda dapat melatih dan membandingkan beberapa jenis model machine learning secara bersamaan. LazyPredict dapat digunakan untuk model klasifikasi maupun regresi. Lebih lanjut, library LazyPredict mengkaji model berdasarkan berbagai metrik, yaitu akurasi, F1 Score, dan waktu eksekusi.
FLAML
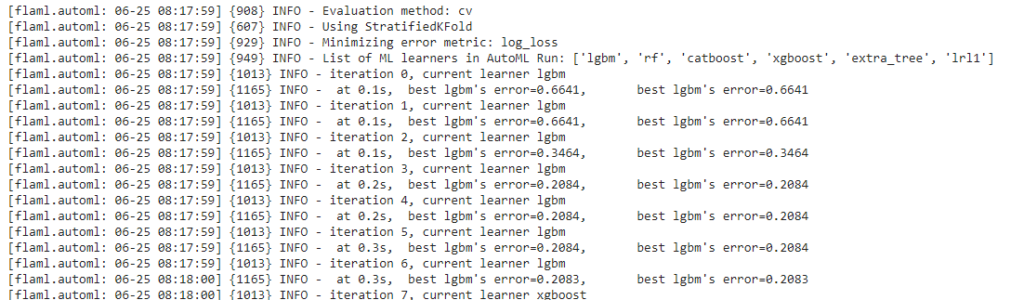
Sama halnya dengan LazyPredict, FLAML juga memungkinkan Anda untuk membandingkan beragam model machine learning. Perbedaannya terletak pada fakta bahwa library FLAML tidak hanya melakukan perbandingan model, tetapi juga membantu Anda dalam melakukan tuning hyperparameter dan memilih model terbaik.
FLAML merupakan sebuah library yang dikembangkan oleh Microsoft. Library ini menggunakan sistem optimisasi hyperparameter dan seleksi model yang dikembangkan oleh Microsoft Research.
Dalam kerangka FLAML, model bawaan seperti LightGBM, XGBoost, dan Random Forest telah disediakan. Selain itu, Anda juga dapat menambahkan model lain sesuai kebutuhan dan menentukan batasan waktu untuk melatih model tersebut.
PyCaret

Library ini dibuat dengan tujuan untuk menghemat waktu yang Anda habiskan untuk menulis kode dan mengalokasikan lebih banyak waktu untuk menganalisis data secara mendalam. PyCaret merupakan alat yang dapat membantu Anda dalam mengotomatisasi proses machine learning.
PyCaret mengotomatisasi berbagai tahap, termasuk feature engineering, penanganan missing value, tuning hyperparameter, bahkan proses deployment model. Selain itu, PyCaret juga menyediakan beragam fungsi untuk melakukan normalisasi, scaling, feature selection menggunakan Principal Component Analysis (PCA), menghilangkan outlier, dan masih banyak fungsi lain yang dapat digunakan ketika melakukan data preparation.
Ketika Anda melatih model, Anda memiliki fleksibilitas untuk menambah atau mengurangi model, mengatur batasan waktu, membandingkan berbagai model, dan membuat berbagai grafik, seperti kurva ROC.
Salah satu fitur luar biasa lainnya adalah kemampuan untuk dengan mudah mendeploy model yang telah dibuat ke platform cloud populer seperti AWS, Google Cloud Platform (GCP), dan Microsoft Azure. Selain itu, Anda juga dapat menyimpan model yang telah dilatih sebagai file pickle, sehingga Anda dapat menggunakannya kapan saja sesuai kebutuhan Anda.
Kesimpulan
Library di atas dapat digunakan untuk mengotomatisasi berbagai tahap, mulai dari persiapan data hingga deployment model. Meskipun sangat bermanfaat, sebaiknya seluruh rangkaian proses ini tetap dilakukan secara manual. Hal ini penting agar Anda tidak melewatkan insight penting mengenai data yang dapat berujung pada kesalahan dalam pelatihan model. Oleh karena itu, library di atas hendaknya hanya digunakan apabila Anda memiliki waktu pengerjaan yang terbatas.
Jika Anda tertarik untuk menggali lebih dalam mengenai bidang data science serta menjadikannya sebagai karir yang gemilang hingga menjadi #JadiTalentaData, maka Anda dapat bergabung ke dalam Bootcamp Algoritma Data Science. Bootcamp ini menawarkan rangkaian program yang memandu Anda untuk memahami seluruh aspek dunia data dalam industri yang anda minati. Ayo, jangan lewatkan kesempatan ini untuk bergabung dengan Algoritma sekarang!
MICHELLE INTAN HANDA





