
8 Metrik untuk Mengukur Performa Model Machine Learning
Ketika membuat Machine Learning penting untuk mengukur seberapa baik model melalui pemilihan metrik yang sesuai. Yuk pahamin bersama dalam berikut!
Table of Contents
Metrik dalam Machine Learning merupakan alat yang digunakan untuk mengukur kinerja atau kualitas model (to measure the performance of model) dalam memprediksi hasil. Prediksi model atau output yang dihasilkan melalui model yang dilatih dengan dataset akan diberikan sebuah skor (score) rangka meninjau model terbaik dari berbagai pilihan algoritma.
Dalam artikel ini, kita akan menjelajahi berbagai metrik yang digunakan untuk mengukur performa model Machine Learning dan pentingnya memahami metrik evaluasi tersebut dalam mengevaluasi model.
Mengapa Machine Learning Membutuhkan Metrik?
Machine learning membutuhkan metrik karena metrik merupakan alat yang digunakan untuk mengukur dan mengevaluasi kinerja model atau sistem yang dikembangkan menggunakan machine learning. Metrik memberikan cara objektif untuk menilai sejauh mana model dapat melakukan tugas yang diminta atau memprediksi dengan akurasi tertentu.
Dalam konteks machine learning, metrik digunakan untuk mengukur sejauh mana model mampu mempelajari pola-pola yang ada dalam data training dan menerapkannya pada data yang belum pernah dilihat sebelumnya (data validation dan testing). Metrik juga membantu dalam membandingkan performa antara beberapa model atau pendekatan yang berbeda, sehingga memungkinkan pemilihan model yang paling sesuai dengan kebutuhan dan tujuan yang diinginkan.
Dengan demikian, Machine Learning sangat membutuhkan metrik karena untuk menguji kualitas model Machine Learning apakah layak diproduksi atau digunakan secara luas (deployment) dan menjadi acuan dalam menentukan berbagai algoritma atau model Machine Learning dalam rangka memilih model yang paling sesuai kebutuhan dan tujuan.
Metrik yang Sering Digunakan untuk Machine Learning
Setelah kita memahami alasan Machine Learning membutuhkan metrik, sekarang kita akan mempelajari apa saja metrik yang populer dalam Machine Learning. Tentunya ketika kita berbicara metrik Machine Learning itu sangat banyak ya sehingga pada kesempatan kali ini kita hanya akan mengulas metrik untuk mengevaluasi 2 kasus umum dalam Machine Learning, yakni regresi (regression) dan klasifikasi (classification).
A. Model Regresi
Regresi merupakan salah satu kasus untuk memprediksi suatu nilai kontinu berdasarkan variabel-variabel input yang ada. Berikut ini adalah beberapa contoh metrik yang sering digunakan dalam regresi:
1. Mean Squared Error (MSE)
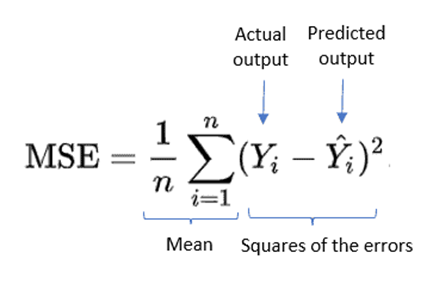
MSE mengukur rata-rata dari selisih kuadrat antara nilai prediksi dan nilai yang sebenarnya. Metrik ini memberikan bobot yang lebih besar pada perbedaan antara prediksi dan nilai yang sebenarnya. MSE dihitung dengan menjumlahkan selisih kuadrat antara prediksi dan nilai yang sebenarnya, kemudian membaginya dengan jumlah total prediksi.
2. Mean Absolute Error (MAE)
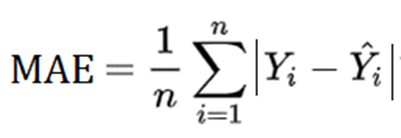
MAE mengukur rata-rata dari selisih absolut antara nilai prediksi dan nilai yang sebenarnya. Metrik ini memberikan gambaran tentang sejauh mana model "meleset" dalam memprediksi nilai kontinu atau dikenal dengan sebutan error. MAE dihitung dengan menjumlahkan selisih absolut (dibulatkan hasilnya menjadi positif) antara prediksi dan nilai yang sebenarnya, kemudian membaginya dengan jumlah total prediksi.
3. Root Mean Squared Error (RMSE)
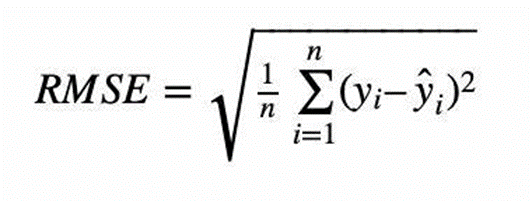
RMSE merupakan akar kuadrat dari MSE dan digunakan untuk memberikan ukuran yang lebih interpretatif karena memiliki satuan yang sama dengan variabel target yang diukur. Metrik ini memberikan gambaran tentang sejauh mana model "meleset" (error) dalam memprediksi nilai kontinu dengan mengurangi efek kuadrat dari MSE.
4. R-Squared (R2)
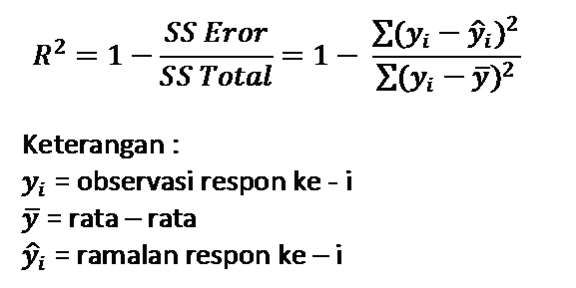
R-Squared mengukur sejauh mana variabilitas dalam variabel target dapat dijelaskan oleh model. Metrik ini memberikan informasi tentang persentase variasi dalam variabel target yang dapat dijelaskan oleh variabel input yang digunakan dalam model.
Dapat dihitung dengan mencari nilai SS Eror yang didapat dari menjumlahkan selisih kuadrat nilai sebenarnya observasi dengan nilai prediksi dan nilai SS Total yang didapat dari menjumlahkan selisih kuadrat nilai sebenarnya observasi dengan nilai rata-rata data. Setelah itu, 1 dikurangi nilai SS Eror dibagi SS Total.
Nilai R-Squared berkisar antara 0 dan 1, dimana nilai semakin mendekati 1 menunjukkan bahwa model semakin dapat menjelaskan semua variasi dalam data alias semakin baik.
B. Model Klasifikasi
Klasifikasi adalah teknik dalam machine learning yang digunakan untuk mengelompokkan data ke dalam kategori atau kelas yang telah ditentukan berdasarkan atribut-atribut yang ada.
Sebelum kita membahas berbagai metrik dibawah, penting untuk memahami beberapa kata kunci seperti True Positive (TP), True Negative (TN), False Positive (FP) dan False Negative (FN). Kata True dan False merujuk pada apakah prediksi yang dilakukan benar atau salah. Sedangkan Positive dan Negatif merujuk pada kondisi, biasanya positive bermakna lebih dapat ditoleransi dibandingkan negative karena berbahaya.

Contohnya, semisal mendeteksi kehamilan (pregnant), kalau false positive berarti memprediksi seorang laki-laki hamil padahal tidak sehingga ia mesti lebih menjaga kesehatan (dampaknya masih positif), sedangkan false negative berarti memprediksi seorang perempuan tidak hamil padahal hamil sehingga ia tidak melakukan perawatan yang mungkin khusus terkait ibu hamil (dampaknya negatif).
Penentuan positive dan negative memang tricky dan butuh disesuaikan dengan kasus yang akan diklasifikasikan. Istilah True Positive (TP), True Negative (TN), False Positive (FP) dan False Negative (FN) tergambar pada tabel yang disebut Confusion Matrix di bawah ini.
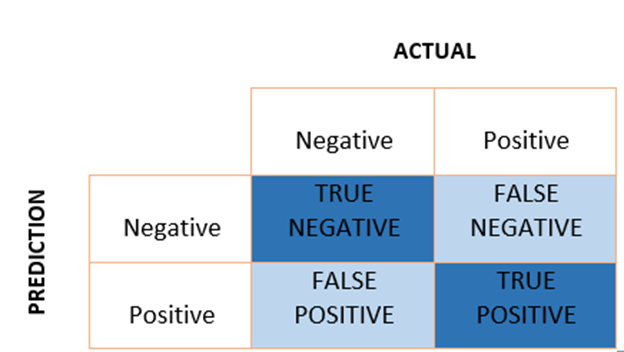
• True Positive (TP) adalah prediksi positif yang benar oleh model.• True Negative (TN) adalah prediksi negatif yang benar oleh model.• False Positive (FP) adalah prediksi yang salah dari model yang positif.• False Negative (FN) adalah prediksi negatif yang salah dari model.
Contoh Metrik yang Sering Digunakan
Berikut ini adalah beberapa contoh metrik yang sering digunakan:
1. Akurasi (Accuracy)
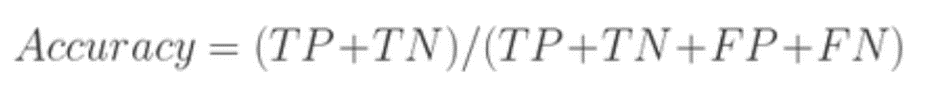
Metrik ini mengukur sejauh mana model dapat mengklasifikasikan data dengan benar dibandingkan dengan total jumlah prediksi. Akurasi dihitung dengan membagi jumlah prediksi yang benar dengan jumlah total prediksi. Misalnya, jika model berhasil mengklasifikasikan 90 data dengan benar dari total 100 data, maka akurasinya adalah 90%.
2. Presisi (Precision)
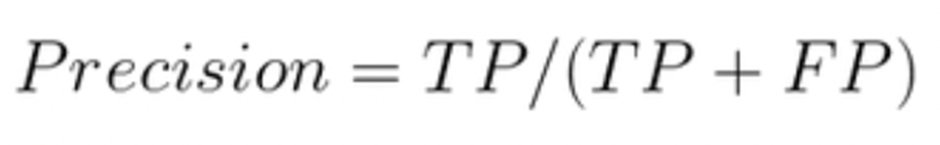
Presisi mengukur sejauh mana hasil prediksi positif yang diberikan oleh model adalah benar. Metrik ini menghitung perbandingan antara jumlah True Positive (TP) dengan jumlah total prediksi positif (TP + FP). Presisi memberikan indikasi tentang seberapa "baik" atau seberapa sedikit "kesalahan" yang dihasilkan oleh model dalam memberikan prediksi positif.
3. Recall (Recall)
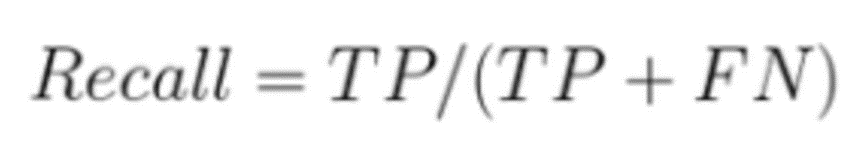
Recall mengukur sejauh mana model dapat mengidentifikasi dengan benar semua hal positif yang ada. Metrik ini menghitung perbandingan antara jumlah true positive (TP) dengan jumlah total nilai yang sebenarnya alias nilai aktual(TP + FN). Recall memberikan gambaran tentang kemampuan model dalam "mengingat" atau mendeteksi data positif secara keseluruhan.
4. F1-Score
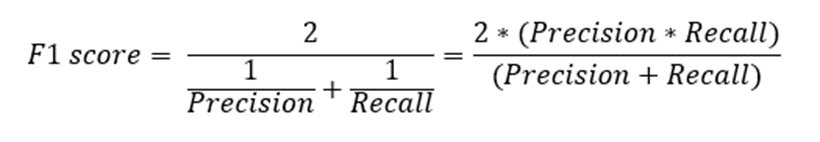
F1-score adalah ukuran gabungan antara presisi dan recall. Metrik ini memberikan keseimbangan antara kedua metrik tersebut dan berguna ketika kita ingin mencapai keseimbangan antara presisi dan recall. F1-score dihitung dengan 2 dikali dengan nilai perkalian precision dan recall kemudian dibagi dengan nilai penjumlahan precision dan recall.
Kesimpulan
Metrik merupakan alat untuk mengukur dan mengevaluasi kinerja model atau sistem yang dikembangkan menggunakan machine learning (performance of a machine learning model). Harapannya dengan metrik ini dapat membantu pemilihan model yang paling relevan dengan kebutuhan ataupun sebagai acuan sebelum digunakan secara luas (deployment).
Pada artikel ini kita sudah membahas kinerja model (model performance) untuk jenis Regresi dan Klasifikasi. Pada model regresi terdiri dari 4 contoh, yakni Mean Squared Error (MSE), Mean Absolute Error (MAE), Root Mean Squared Error (RMSE) dan R-Squared (R2). Sedangkan pada model klasifikasi terdiri dari 4 contoh juga, yakni Akurasi (Accuracy), Presisi (Precision), Recall (Recall), dan F1-Score.
Jika Anda tertarik mempelajari cara mengembangkan, mengevaluasi dan pemanfaatan Machine Learning lebih lanjut hingga #JadiTalentaData handal, Anda dapat mengikuti Bootcamp Algoritma DataScience yang memiliki serangkaian program yang dapat membantu Anda menguasai dunia data di industri yang Anda minati. Yuk, bergabung bersama Algoritma sekarang!




